Introduction
Project stages
En noviembre de 2016, el proyecto de investigación Diccionario del Español Medieval electrónico (DEMel) inició su labor con el propósito de digitalizar el extenso e inédito material de datos del Diccionario del Español Medieval (DEM) y permitir el acceso libre al usuario a través de la web. En varias etapas del proyecto, el material de datos compuesto por unas 865 000 fichas se convirtió en un archivo digital y se hizo accesible para su uso posterior. Con la finalización del proyecto en abril de 2026, el archivo del DEM ya está disponible como conjunto de datos de investigación digitales interoperables.
1. Primera etapa del proyecto
La primera etapa del proyecto (noviembre de 2016 - octubre de 2020) tenía como objetivo principal conservar el material a largo plazo, publicarlo en la web y facilitar la búsqueda en el archivo. Para ello, primero se digitalizaron todas las fichas. Después, se introdujo en una base de datos la información más importante anotada en las aproximadamente 700 000 fichas de documentaciones. Al final, se desarrolló la interfaz de usuario para la recuperación de datos. Estos pasos se explican a continuación con más detalle.
1.1. Preparación del proceso de digitalización y escaneo
De noviembre de 2016 a mayo de 2017, el material de datos se preparó en la sede de Paderborn para el proceso de escaneo en una empresa externa. El trabajo preparatorio consistió, entre otras cosas, en quitar clips y grapas, reparar fichas, hacer copias de los dorsos escritos y la clasificación preliminar de papeles con distintos formatos (por ejemplo, DIN A4). Entre diciembre de 2016 y noviembre de 2017, todo el material fue escaneado por la empresa externa. Se produjeron un total de 869 020 archivos de imagen en formato TIFF con una resolución de 300 ppp en relación con el tamaño original con una profundidad de color de 24 bits, nombrados por numeración ascendente y entregados a Rostock en discos duros portátiles. Por último, todo el material de datos físicos se trasladó a Rostock y se archivó en el centro de investigación.
 |
 |
1.2. Base de datos y aplicación de registro de datos
Los archivos de imágenes obtenidos se importaron y guardaron sucesivamente en el sistema de digitalización Goobi.Production de la Biblioteca Universitaria de Rostock mediante un programa de importación. Gracias a las funcionalidades de Goobi, fue posible poner inmediatamente a disposición del proyecto el gran número de datos y comprobar la calidad y la totalidad del material digitalizado. El primer procesamiento del material a partir de junio de 2017 también se realizó con Goobi: los lemas y sus imágenes asociadas se registraron como "secciones de lemas". Para ello, los editores trasladaron a la base de datos la clasificación existente del material por lemas creando una jerarquía a nivel de palabras clave, es decir, separando las secciones pertenecientes a diferentes lemas entre sí.
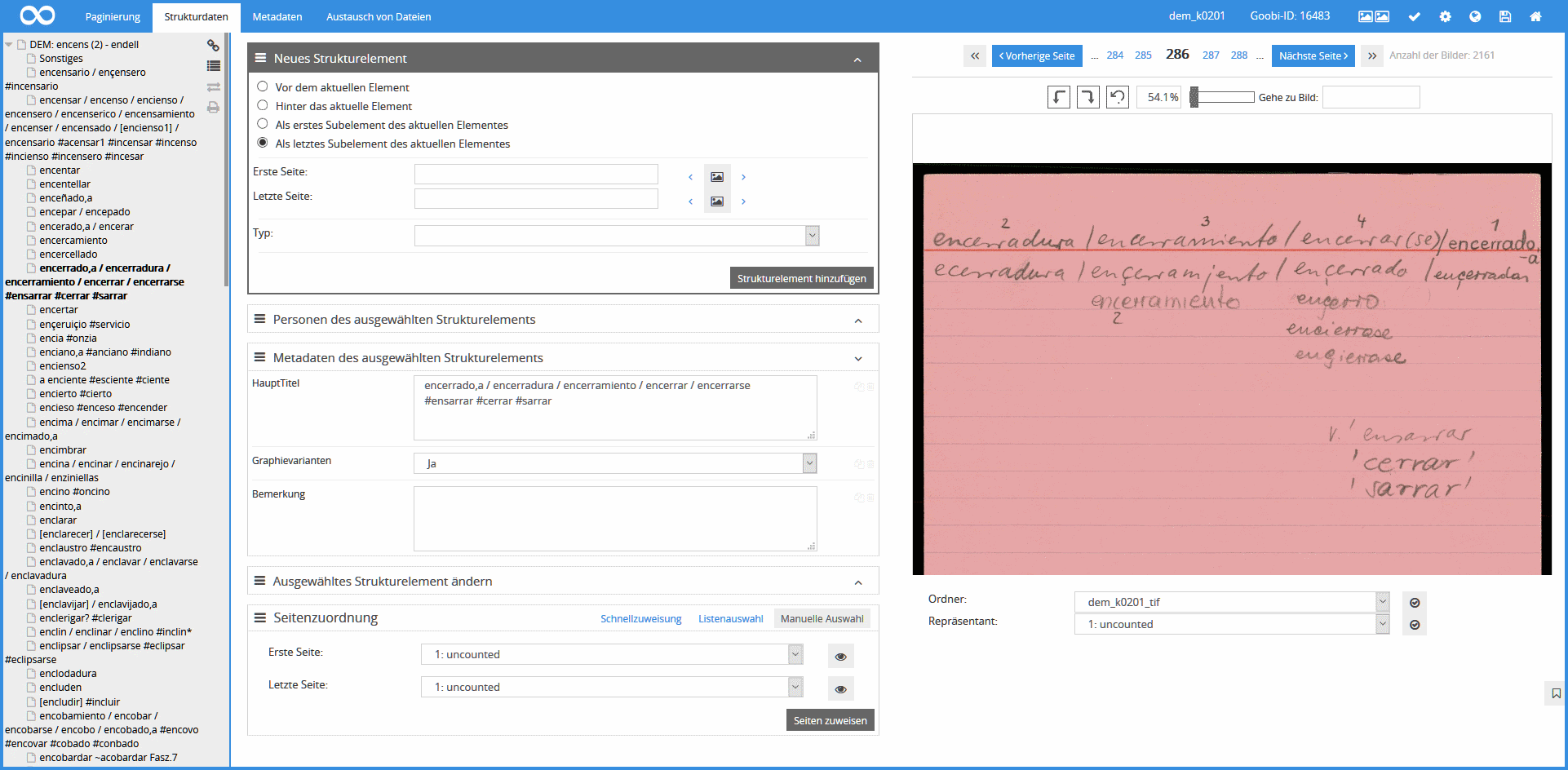
Para el procesamiento posterior, los datos se importaron de Goobi a un repositorio MyCoRe de la Biblioteca de la Universidad de Rostock. Mediante un programa de importación se generaron imágenes derivadas para la presentación (archivos JPG con pies de página que incluye enlace de citación, logotipo de financiación, etc.), estructuras de archivo y metadatos (archivos METS con información estructural, sumas de comprobación, etc.). A través de interfaces estandarizadas, los archivos de imagen están ahora disponibles para su uso en la aplicación del registro de datos y en el portal DEMel. Para registrar los datos, se implementó un modelo relacional en un sistema de base de datos relacional (MySQL) que incluye las entidades relevantes y sus relaciones: gavetas (objetos de archivo) y fichas (archivos de imágenes), entradas bibliográficas (obras, ediciones, siglas), lemas y documentaciones, así como datos administrativos y de configuración.
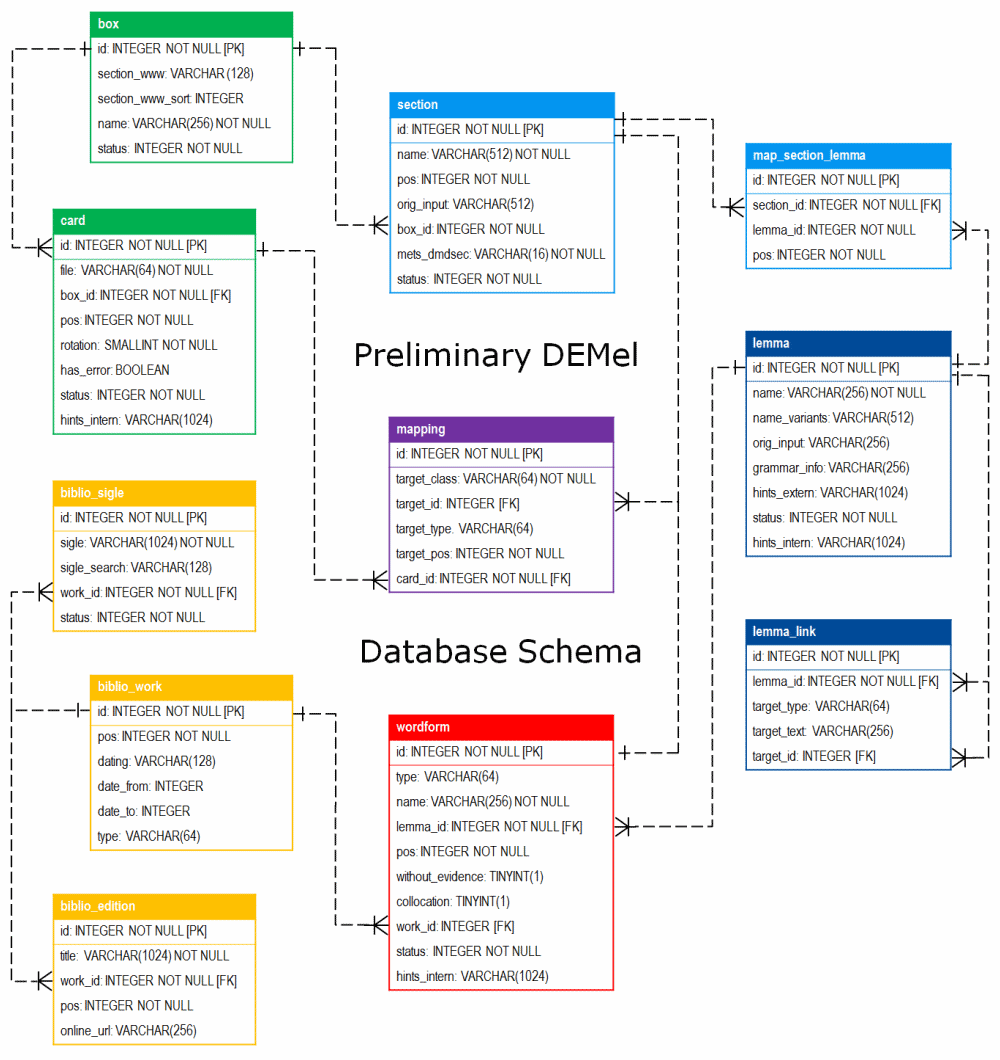
En marzo de 2018, se inició el registro de los datos de las imágenes mediante la aplicación web especialmente desarrollada para este proyecto. Con el fin de que la información anotada en las fichas pudiera ser buscada posteriormente, los colaboradores del proyecto -principalmente estudiantes y asistentes de investigación de las universidades de Paderborn y Rostock- introdujeron en la aplicación de registro una selección fija de la información que figuraba en las fichas. Para respetar el plazo del proyecto, sólo se disponía de unos 30 segundos de media por imagen para identificar e introducir la información pertinente en la base de datos. En total, se procesaron manualmente unos 700 000 archivos de imágenes de esta manera y los datos extraídos se almacenaron en la base de datos. Los colaboradores que registraron los datos recibieron un manual con 80 páginas de directrices para el registro de datos, que se recopiló y actualizó continuamente en el marco del proyecto. Los datos registrados fueron comprobados aleatoriamente por los coordinadores del proyecto y, en caso necesario, se volvieron a procesar.
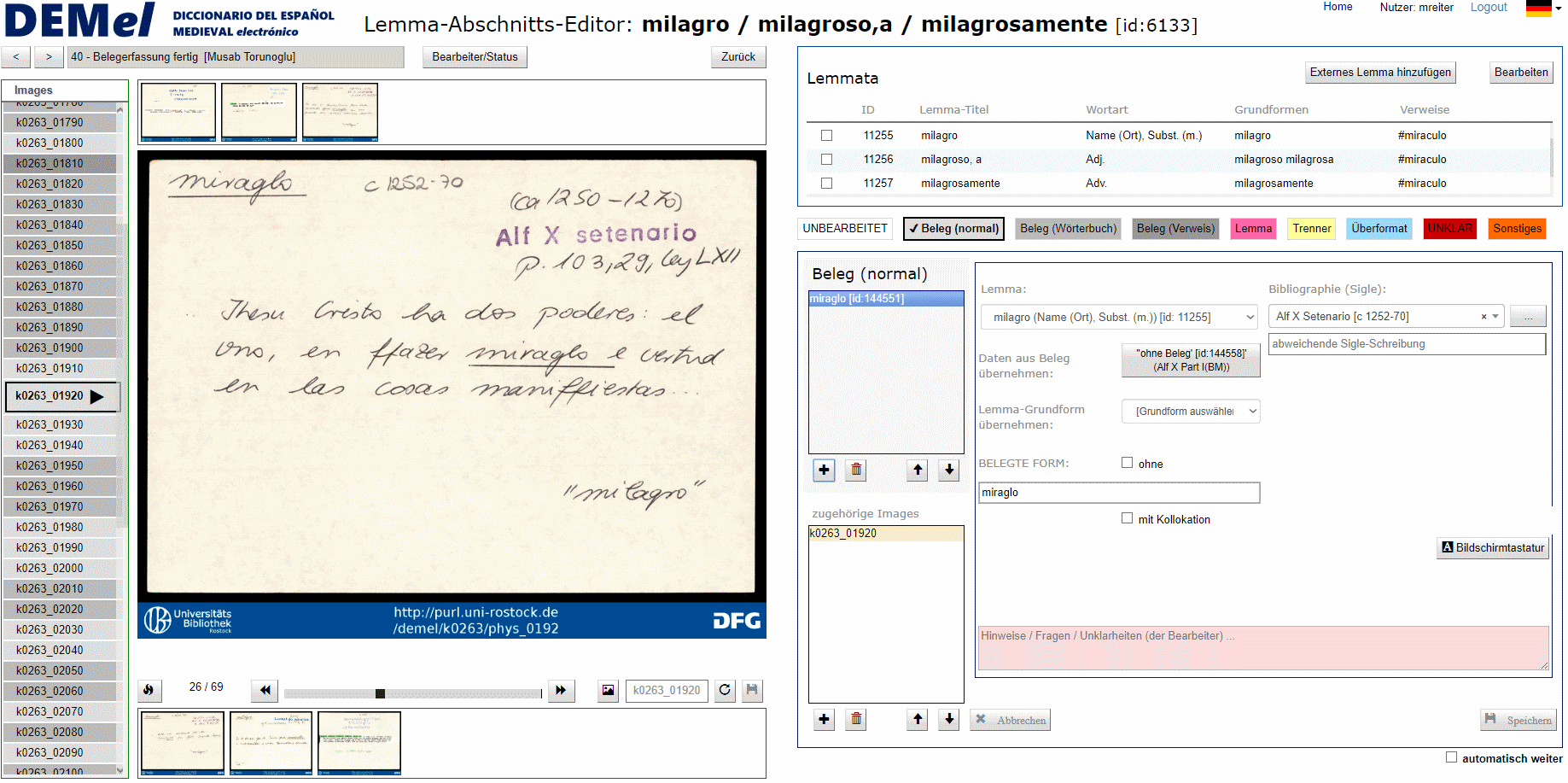
En el transcurso del registro de datos, se puso de manifiesto que la bibliografía del DEM, que constituye la base de la del DEMel, no estaba completa. Por lo tanto, había que descodificar más de 650 siglas no registradas e investigar los datos bibliográficos correspondientes. En algunos casos, sólo se anotaron como siglas palabras clave individuales o combinaciones de letras y dígitos, cuya resolución requirió un trabajo considerable. Además, dado que a menudo se utilizaban diferentes siglas para una obra -circunstancia que dificultaba la selección de la sigla correcta en el curso de la introducción de datos-, había que identificar todas las variantes con el mismo significado. Las siglas "CartNájera" y "F y C-Pueblas", por ejemplo, se refieren ambas a la misma edición de Narciso Hergueta de 1898. En unos 550 casos de este tipo, la bibliografía se amplió para incluir las siglas divergentes más relevantes.
 |
 |
"CartNájera" = "F y C-Pueblas" = Narciso Hergueta, Fueros y cartas-pueblas de Santoña, Alesón, Torecilla de Cameros, San Andrés de Ambrosero, Oriemo, ETC., en: BRAH 33, 1898, 122-140.
Además de las diferentes siglas, hubo otros aspectos que plantearon un reto durante el registro de datos. Por ejemplo, las fichas escritas a mano, que en ocasiones eran difíciles de leer, planteaban problemas para diferenciar entre las letras de aspecto similar, por ejemplo u↔v y u↔n. En el caso de las fichas especialmente difíciles de descifrar, hubo que comprobar la escritura en las fuentes. Además, en bastantes casos no era fácil saber a primera vista si una ficha era una documentación primaria o secundaria. La forma de tratar estos casos se explica con más detalle en la Metodología de registro. Por último, las fichas de documentaciones que estaban clasificadas en secciones de lemas equivocadas dificultaban la introducción de datos. Estos debían vincularse al lema correcto en un paso adicional. Una tarea permanente para garantizar la calidad de los datos fue la aclaración de los casos problemáticos, que los colaboradores en la introducción de datos habían indicado. Además, se realizaron consultas sistemáticas en la base de datos para detectar incoherencias o errores, que pudieron corregirse de forma semiautomática en el conjunto de datos.

¿u o n? La legibilidad de las fichas escritas a mano como problema en el registro de las documentaciones
1.3. Concepción y desarrollo de la interfaz de usuario basada en la web
Paralelamente al proceso de registro de datos, en noviembre de 2018 se inició la concepción y el desarrollo del portal DEMel con la interfaz para la búsqueda de datos. Dos principios de diseño estaban en primer plano: las herramientas de búsqueda que se desarrollaran debían permitir a los usuarios maximizar el uso de los datos registrados según sus intereses individuales de investigación y al mismo tiempo garantizar un manejo lo más intuitivo posible. Para ello, las opciones de búsqueda del portal web permiten a los investigadores realizar evaluaciones precisas y exhaustivas del archivo de datos. Se han realizado y se siguen realizando mejoras en el diseño y la funcionalidad. Para explicar a los usuarios la historia del proyecto DEM o DEMel, el alcance y las funciones de DEMel, la sección Introducción se diseñó como página de información. El núcleo del portal DEMel lo conforman las opciones de búsqueda de lemas y documentaciones. En el desarrollo de las herramientas de búsqueda se hizo especial hincapié en tener en cuenta los requisitos y expectativas de la funcionalidad de una infraestructura de información lexicográfica desde el punto de vista del usuario. En concreto, esto significa que las máscaras de búsqueda y de filtrado se diseñaron para que, por un lado, fueran fáciles de usar sobre la base de las convenciones de diseño de la lexicografía digital y para satisfacer la exploración científica exhaustiva del material de datos, por otro. La integración de la Bibliografía y el Fichero digitalizado también se centró en la comodidad del usuario y la recuperación de la información. Para ello, se han perfeccionado permanentemente las funcionalidades del sitio web y los textos explicativos.
2. Segunda etapa del proyecto
En la segunda etapa del proyecto (noviembre de 2020 - abril de 2023), se continuó trabajando en optimizar la aplicación web, implementando funcionalidades para el registro de datos, la descarga y feedback. También en lo que se refiere a la base de datos, la segunda etapa siguió directamente a la primera: Tras haber registrado inicialmente solo una pequeña selección de información de las fichas por falta de tiempo, la segunda fase del proyecto se dedicó a ampliar, profundizar y consolidar esta base de datos. Esto incluyó una revisión exhaustiva de la bibliografía en la que se añadieron nuevos campos de datos y se enriqueció la información ya existente con registros de autoridad.
2.1. Ampliación del registro de datos
Durante el registro de datos, en la primera etapa del proyecto solo se tuvieron en cuenta las fichas del Fichero DEM nuclear, para que la carga de trabajo fuera manejable. Además, se registró solo el lema con la categoría gramatical, la forma documentada y la fuente de cada documentación y se marcó si había o no una unidad pluriverbal. La segunda etapa del proyecto ofreció la oportunidad de introducir más datos de las fichas en la base de datos e incluir más imágenes en el registro:
- En primer lugar, se procesaron otras 43.000 imágenes con documentaciones secundarias procedentes de los Vocabularios I. Para ello, se pudo recurrir a la aplicación web del registro de datos de la primera etapa. Tras unos pequeños ajustes y la importación de las fichas digitalizadas y los metadatos correspondientes, se empezó a registrar las documentaciones en enero de 2021. En 8 meses, se añadieron a la base de datos un total de 37 443 nuevas entradas. Ahora se pueden consultar también en el portal DEMel.
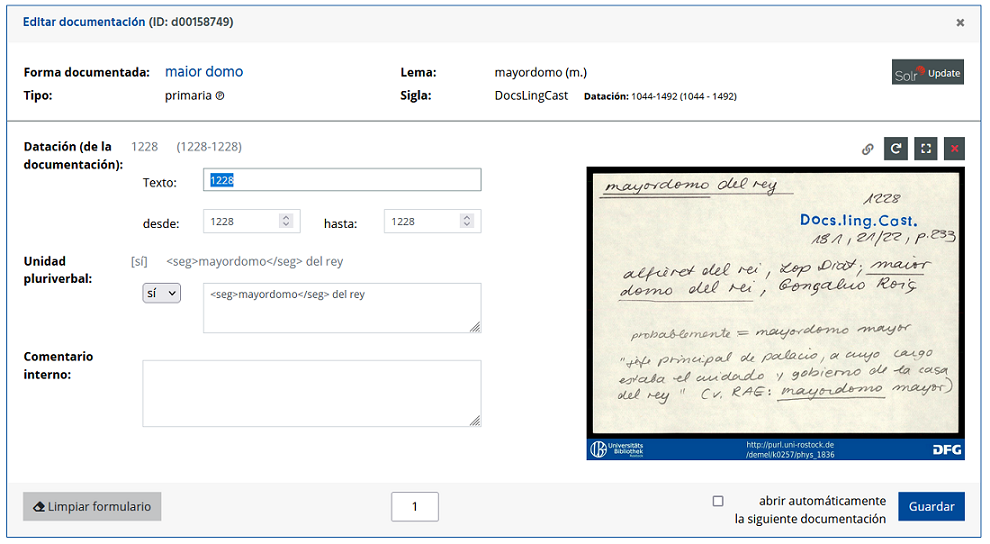
- Posteriormente, se precisó la datación de las documentaciones que en la primera fase solo se generaba automáticamente a partir de la fuente. Sin embargo, en el caso de las documentaciones procedentes de colecciones de textos, la datación más precisa del documento fuente se encuentra normalmente en la imagen de la ficha asociada. Por ello, para preparar el registro de las dataciones, se comprobó en qué fuentes se daba este caso. Se identificaron 272 fuentes que estaban enlazadas con unas 110 000 documentaciones. Con el fin de introducir las fechas en la base de datos, el portal DEMel se amplió con una primera versión de un editor. Este se utilizó entre octubre de 2021 y febrero de 2022 para registrar las dataciones.
- El mismo editor se usó también para las unidades pluriverbales. En la primera etapa del proyecto, el equipo filológico ya había marcado las documentaciones que contenían unidades pluriverbales. En la segunda fase, se registraron las aproximadamente 57 500 unidades pluriverbales en sí. Como resultado, ahora se pueden buscar automáticamente.
2.2. Revisión de la bibliografía
Tras completar la bibliografía en la primera fase del proyecto, al final de la segunda se llevó a cabo una revisión exhaustiva con el objetivo de enriquecerla con más información y mejorar las opciones de búsqueda. Para esto, primero se buscaron sistemáticamente reproducciones digitales de las fuentes disponibles en la web que se enlazaron con la edición respectiva. Después, se incluyeron nuevos campos de datos en la bibliografía, como tipo de texto, lengua, género y autor. Los datos correspondientes se registraron para todas las fuentes primarias, utilizando como referencia el Old Spanish Textual Archive (OSTA) y la Bibliografía Española de Textos Antiguos (BETA). Por último, se referenciaron registros de autoridades (por ejemplo de la Biblioteca Nacional de España) en las entradas bibliográficas. Para todos estos cambios, se revisó el modelo de datos del DEMel. En la parte de la bibliografía, se añadieron las entidades "reproducciones" y "personas" a las "fuentes", "ediciones" y "siglas".

2.3. Optimización del portal DEMel
En la segunda etapa del proyecto, se siguió desarrollando la aplicación web hasta convertirla en una versión madura. Aparte de las búsquedas, los filtros y las facetas, se optimizaron las listas de resultados, los visores de imágenes y las vistas detalladas. Además, se implementaron las siguientes nuevas funcionalidades:
- Como ya se ha mencionado, se implementó un editor para el registro y la edición de datos en la aplicación web. Al principio, solo estaba pensado para introducir las unidades pluriverbales y las dataciones en la base de datos. Después de optimizarlo, se pueden editar con él también otros campos de datos de las documentaciones y los lemas.
- Gracias a una función de feedback, los usuarios tienen la posibilidad de señalar errores o hacer comentarios públicos en el Lemario, en las Documentaciones y en la Bibliografía. Esta función también se utiliza para documentar los cambios en la base de datos.
- La nueva información registrada en la bibliografía y en las documentaciones exigió una revisión del portal DEMel. Esto incluyó tanto la adaptación al modelo de datos actual como la visualización de los nuevos datos y el desarrollo de los filtros correspondientes. Ahora se puede ordenar, por ejemplo, la tabla de las documentaciones según su datación o seleccionar las entradas bibliográficas según su tipo de texto. De este modo, los ajustes permiten realizar búsquedas aún más específicas dentro de la base de datos. Las interfaces para la descarga de datos también se adaptaron al modelo de datos actual.
3. Tercera etapa del proyecto
En la tercera fase del proyecto (mayo de 2023 - abril de 2026), el objetivo principal fue registrar digitalmente los contextos de las documentaciones y las ubicaciones correspondientes, con el fin de digitalizar toda la información que figura sistemáticamente en las fichas. Para ello, se desarrolló un procedimiento de anotación semiautomática de las documentaciones en los textos fuente. Además, se integraron en el portal DEMel los artículos del diccionario DEM ya publicados. Por último, los datos del DEMel se pusieron a disposición en formatos estándar sostenibles y compatibles para mejorar su interoperabilidad.
3.1 La integración del DEM impreso en el portal DEMel
Gracias a la autorización de la editorial universitaria Winter de Heidelberg, en la tercera fase del proyecto se retrodigitalizaron los tres volúmenes del Diccionario del español medieval (a–almohatac, 1987–2005) y se integraron en el portal DEMel. Tras el escaneo, las aproximadamente 2.000 imágenes se transfirieron al sistema de digitalización Goobi Workflow de la Biblioteca Universitaria de Rostock. Allí se llevó a cabo la paginación y el registro de 50 elementos estructurales —entre ellos la introducción, la bibliografía, el índice de abreviaturas y una clasificación de los artículos del diccionario en secciones alfabéticas— para facilitar la navegación. Para generar texto OCR a partir de las imágenes, se compararon varias herramientas: ABBYY FineReader Engine (a través de Goobi Workflow), Transkribus y OCR4all. Transkribus ofreció los mejores resultados, ya que permitió entrenar tanto un modelo propio para el reconocimiento de texto como otro para el reconocimiento del diseño. A continuación, las imágenes se archivaron junto con los metadatos correspondientes y el texto OCR en RosDok, el repositorio de la Biblioteca Universitaria de Rostock, y se hicieron accesibles a través de interfaces estandarizadas. Mediante URL persistentes (PURL) se pueden citar tanto los volúmenes individuales como el DEM en conjunto. El visor de RosDok se integró en una sección específica del portal DEMel denominada «DEM», donde se pueden hojear los tres volúmenes digitalizados en su totalidad —con portada, prólogo, bibliografía, etc.
Para integrar las entradas del diccionario en la base de datos DEMel solo fue necesario realizar un único cambio en el modelo de datos: el nuevo tipo «print_dem» para las imágenes. Por lo demás, se pudo reutilizar sin modificaciones el modelo de datos diseñado en las fases anteriores del proyecto. Para insertar las entradas en la base de datos, bastaba con conocer el ID de los lemas del DEMel, así como el número del volumen correspondiente y las páginas correspondientes. Con este fin, se rellenó una hoja de cálculo de Excel con una lista generada por la base de datos de los lemas de la a a almohatac y el equipo del proyecto la completó basándose en las entradas publicadas en el DEM. Esta tarea brindó al mismo tiempo la oportunidad de verificar los datos registrados en las fases anteriores del proyecto: se compararon la ortografía y la categoría gramatical de los lemas entre el diccionario impreso y la base de datos. Al hacerlo, se descubrió que 78 lemas registrados en el DEM, junto con sus documentaciones, faltaban en el lemario del DEMel, por lo que se añadieron en consecuencia. Por último, se crearon comandos SQL para introducir las nuevas entradas en la base de datos. Los artículos del diccionario ahora también se pueden encontrar mediante la búsqueda de documentaciones dentro del portal.
En el proceso de digitalización del DEM, se digitalizaron además 12 títulos libres de derechos de autor de la bibliografía del DEMel que hasta ahora no estaban disponibles gratuitamente en la web. Estos documentos digitalizados, que suman un total de unas 5 000 imágenes, se sometieron a un proceso de OCR, se pusieron a disposición a través de RosDok y se vincularon a la bibliografía en el portal del DEMel.