Einführung
Projektablauf
Im November 2016 nahm das DFG-Forschungsprojekt Diccionario del Español Medieval electrónico (DEMel) seine Arbeit mit dem Ziel auf, das umfangreiche und bisher unpublizierte Datenmaterial des Diccionario del Español Medieval (DEM) zu digitalisieren und der internationalen Öffentlichkeit im Internet frei zugänglich zu machen. In mehreren Projektphasen wurde das aus insgesamt rund 865.000 Karteikarten bestehende Datenmaterial in ein digitales Archiv umgewandelt und für die weitere Nutzung erschlossen. Mit dem Projektabschluss im April 2026 steht das Archiv des DEM nun als interoperable digitale Forschungsdaten bereit.
1. Projektphase 1
Die erste Projektphase (November 2016 - Oktober 2020) hatte vor allem die langfristige digitale Sicherung, die Veröffentlichung des Datenarchivs im Internet sowie eine erleichterte Durchsuchbarkeit zum Ziel. Daher wurden zunächst alle Zettel digitalisiert. Im Anschluss wurden die wichtigsten der auf den ca. 700.000 Belegkarten verzeichneten Informationen in einer Datenbank erfasst und die webbasierte Nutzeroberfläche zur Datenabfrage entwickelt. Diese Arbeitsschritte werden im Folgenden näher erläutert.
1.1 Vorbereitung der Digitalisierung und Scanprozess
Von November 2016 bis Mai 2017 wurde das Datenmaterial am Standort Paderborn für den Scanprozess bei einem externen Dienstleister vorbereitet. Die Vorarbeiten bestanden u. a. in der Entfernung von Büro- und Heftklammern, der Reparatur von Karteikarten, der Anfertigung von Kopien beschriebener Rückseiten, der vorläufigen Aussortierung andersformatiger Zettel (z. B. DIN A4). Zwischen Dezember 2016 und November 2017 wurde das gesamte Material von einem Scan-Dienstleister gescannt. Insgesamt wurden 869.020 Bilddateien im TIFF-Format mit einer Auflösung von 300 dpi bezogen auf die Vorlagengröße mit einer Farbtiefe von 24 bit angefertigt, durch aufsteigende Nummerierung benannt und auf portablen Festplatten nach Rostock geliefert. Abschließend wurde das gesamte physische Datenmaterial nach Rostock überführt und in der Forschungsstelle archiviert.
 |
 |
1.2 Datenbank und Datenerfassungsanwendung
Die gelieferten Bilddateien wurden per Importprogramm sukzessive in das Digitalisierungssystem Goobi.Production der Universitätsbibliothek Rostock eingespielt und gesichert. Unter Nutzung der Goobi-Funktionalitäten konnte eine sofortige projektinterne Bereitstellung der großen Datenmengen sowie eine Qualitäts- und Vollständigkeitskontrolle der Digitalisate erfolgen. Auch die erste Bearbeitung des Materials ab Juni 2017 ging mittels Goobi vonstatten: Lemmata und ihre zugehörigen Images wurden als „Lemma-Abschnitte“ erfasst. Dazu wurde die bereits vorhandene Sortierung des Materials nach Lemmata in die Datenbank übernommen, indem die Bearbeiterinnen und Bearbeiter eine Hierarchie auf Stichwortebene anlegten, d. h. die Abschnitte, die zu unterschiedlichen Lemmata gehören, voneinander trennten.
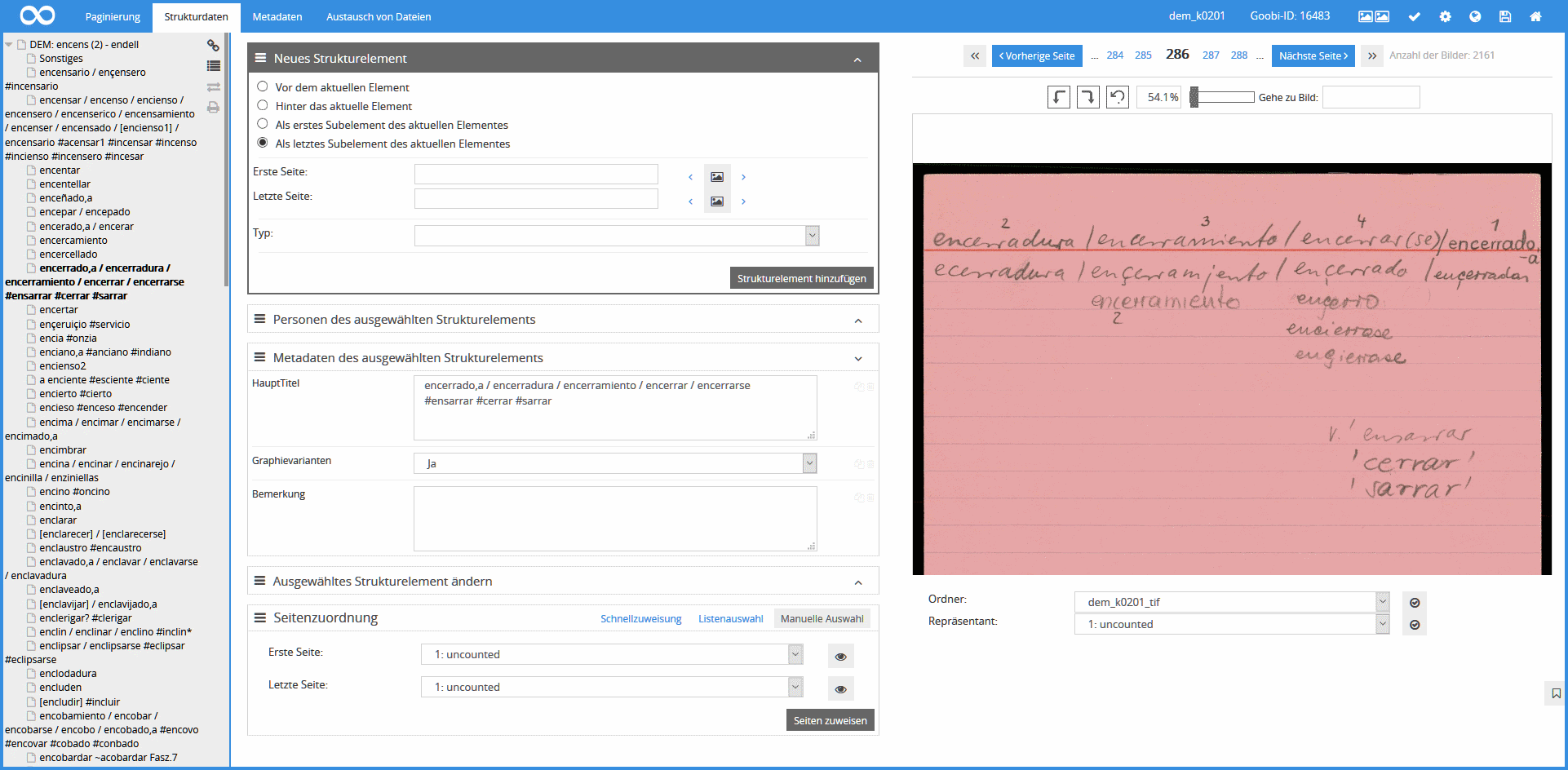
Zwecks weiterer Bearbeitung wurden die Daten aus Goobi in ein MyCoRe-Repositorium der UB Rostock importiert, wobei mit einem Importprogramm Präsentationsderivate (JPG-Dateien mit Fußzeilen inkl. Zitierlink, Fördererlogo etc.), Archivstrukturen und Metadaten (METS-Dateien mit Strukturinformationen, Prüfsummen etc.) generiert wurden. Über standardisierte Schnittstellen stehen die Bilddateien nun zur Nutzung in der Datenerfassungsanwendung und in der Präsentationsanwendung zur Verfügung. Zur Datenerfassung wurde ein Datenmodell in einem relationalen Datenbanksystem (MySQL) implementiert, das die relevanten Entitäten und ihre fünf Beziehungen umfasst: Karteikästen (Archivobjekte) und Zettel (Imagedateien), Bibliografieeinträge (Werke, Ausgaben, Siglen), Lemmata und Belege sowie Verwaltungs- und Konfigurationsdaten.
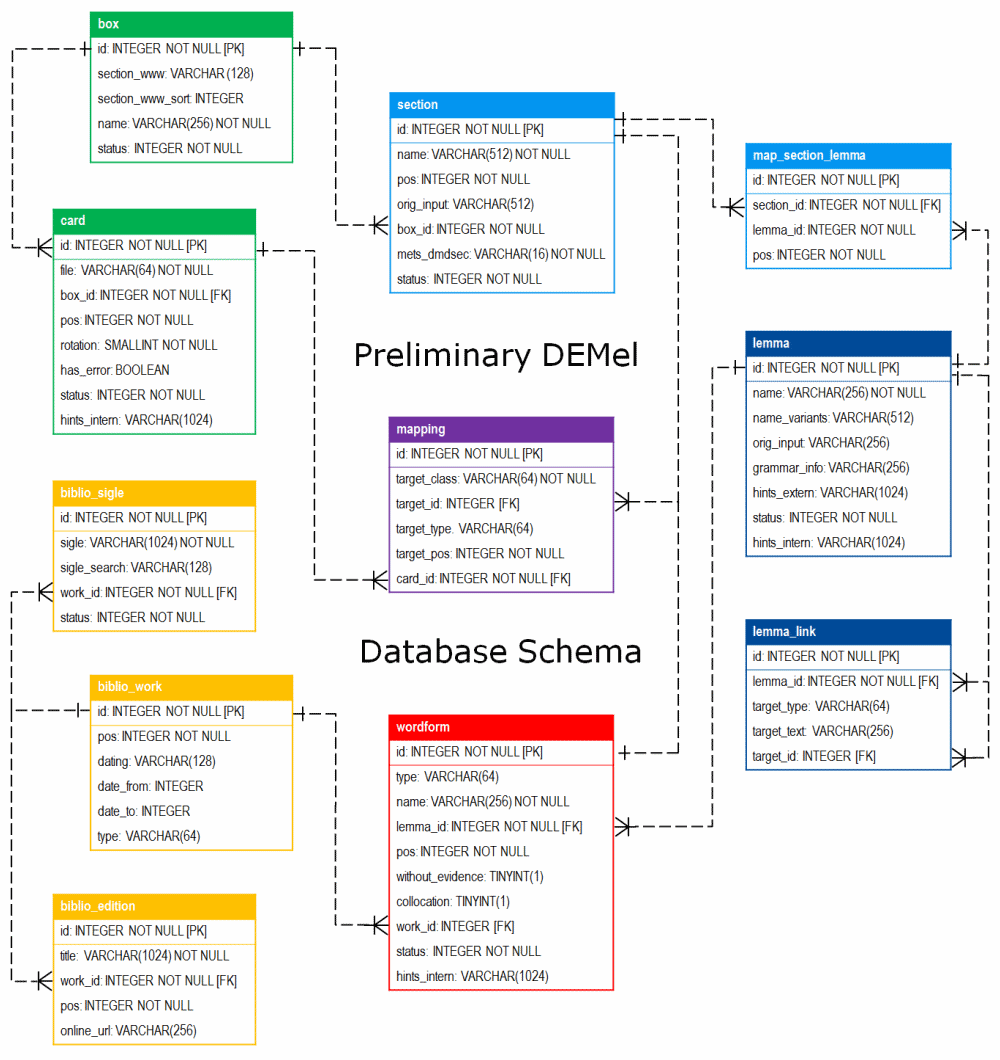
Im März 2018 wurde mit der Erfassung der Daten auf den Images mittels der eigens entwickelten Webanwendung begonnen. Um die auf den Fichas verzeichneten Angaben für eine spätere Abfrage durchsuchbar zu machen, gaben die Bearbeiterinnen und Bearbeiter – vor allem studentische und wissenschaftliche Hilfskräfte der Universitäten Paderborn und Rostock – eine festgelegte Auswahl der auf den Karten aufgeführten Informationen in die Erfassungsanwendung ein. Um den Zeitrahmen des Projekts einzuhalten, standen pro Image im Schnitt nur rund 30 Sekunden zur Identifikation und Erfassung der relevanten Informationen zur Verfügung. Insgesamt wurden auf diese Weise rund 700.000 Bilddateien manuell bearbeitet und die erfassten Daten in der Datenbank gespeichert. Den Datenerfasserinnen und -erfassern stand dabei ein im Rahmen des Projekts erarbeitetes und laufend aktualisiertes, zum Schluss 80 Seiten umfassendes Handbuch mit Erfassungsrichtlinien als Leitfaden zur Verfügung. Die erfassten Daten wurden von der Projektkoordination stichprobenartig überprüft und ggf. nachbearbeitet.
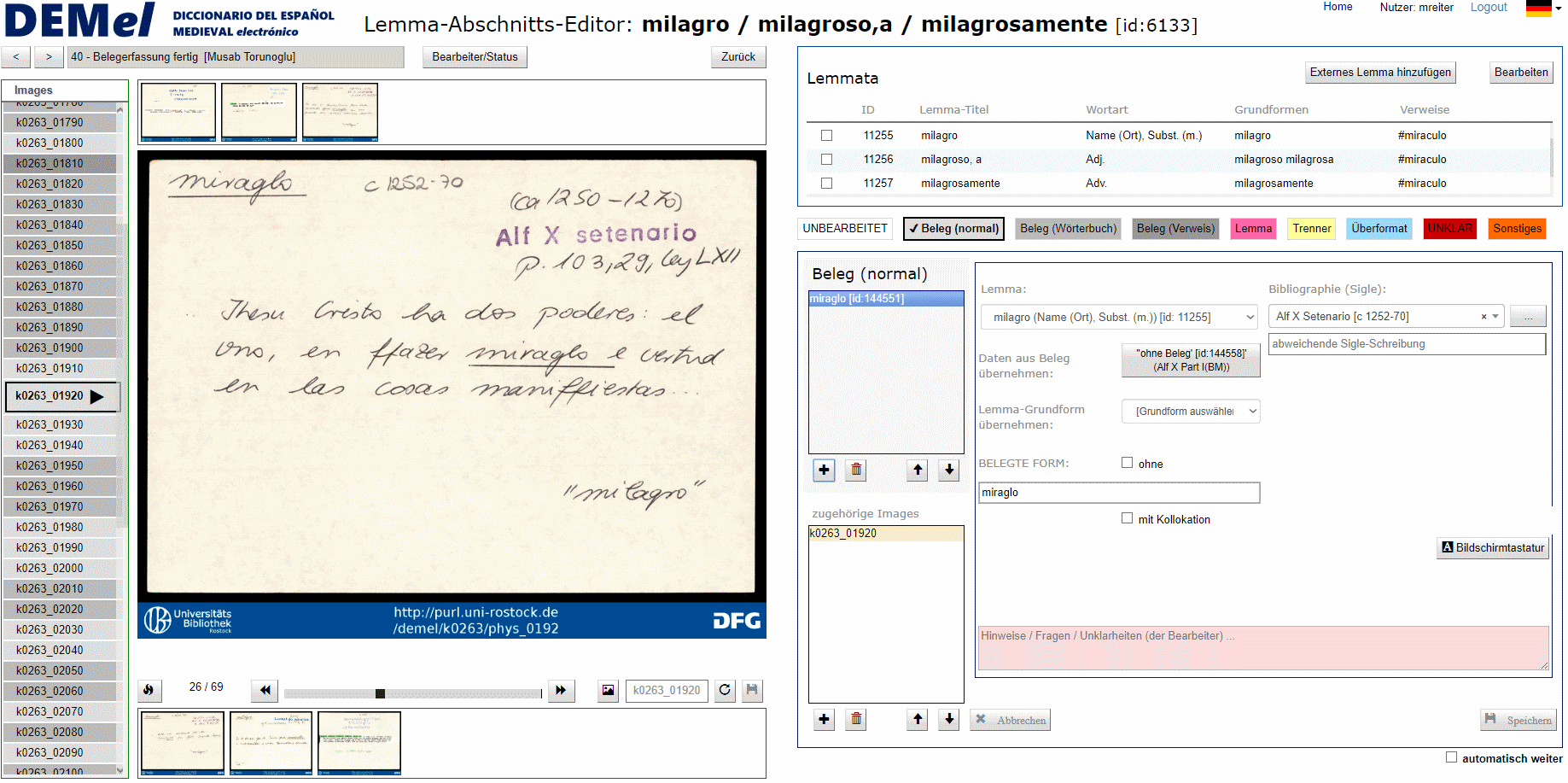
Im Zuge der Datenerfassung zeigte sich, dass die Bibliografie des DEM, die die Grundlage derjenigen des DEMel darstellt, keineswegs vollständig war. So mussten über 650 unregistrierte Siglen entschlüsselt und die entsprechenden bibliografischen Angaben recherchiert werden. Teilweise sind nur einzelne Stichworte oder Buchstaben-Ziffern-Kombinationen als Siglen notiert worden, deren Auflösung einen nicht unerheblichen Arbeitsaufwand erforderte. Da auf den Karteikarten zudem häufig andere Schreibungen der Siglen verwendet wurden als in der Bibliographie – ein Umstand, der die Auswahl der korrekten Sigle im Zuge der Datenerfassung erschwerte –, mussten gleichbedeutende Varianten identifiziert werden. Die Siglen „CartNájera“ und „F y C-Pueblas“ beispielsweise verweisen beide auf dieselbe Textedition Narciso Herguetas aus dem Jahr 1898. In rund 550 derartigen Fällen wurde die Bibliografie zusätzlich um die wichtigsten solcher abweichenden Siglenschreibungen erweitert.
 |
 |
= Narciso Hergueta, Fueros y cartas-pueblas de Santoña, Alesón, Torecilla de Cameros, San Andrés de Ambrosero, Oriemo, ETC., in: BRAH 33, 1898, 122-140.
Neben den abweichenden Siglenschreibungen stellten weitere Aspekte eine Herausforderung bei der Datenerfassung dar. So warfen die stellenweise ohnehin schon schwer lesbaren handgeschriebenen Zettel insbesondere bei der Differenzierung zwischen den ähnlich aussehenden Buchstaben u↔v und u↔n besonders große Probleme auf. Bei besonders schwer entzifferbaren Fichas musste die Schreibung daher in den Quellen überprüft werden. Darüber hinaus war es in einer ganzen Reihe von Fällen nicht einfach, auf den ersten Blick zu erkennen, ob es sich bei einer Karte um einen Primär- oder Sekundärbeleg handelt. Wie in diesen Fällen verfahren wurde, wird ausführlicher in den Erfassungsprinzipien dargelegt. Schließlich erschwerten in den falschen Lemmaabschnitten einsortierte Belegkarten die Datenerfassung, da diese in einem zusätzlichen Arbeitsschritt mit dem richtigen Lemma verknüpft werden mussten. Eine dauerhafte Aufgabe zur Sicherung der Datenqualität bestand in der Klärung von Problemfällen, die von den Datenerfasserinnen und -erfassern angezeigt wurden. Zudem erfolgten systematische Datenbankabfragen nach Inkonsistenzen oder Fehlern, die halbautomatisch im Datenbestand korrigiert werden konnten.

als Problem bei der Belegerfassung
1.3 Konzeption und Entwicklung der webbasierten Nutzeroberfläche
Parallel zum fortschreitenden Prozess der Datenerfassung wurde im November 2018 mit der Konzeption und Entwicklung der DEMel-Internetpräsenz und der Nutzeroberfläche zur Datenabfrage begonnen. Zwei Gestaltungsprinzipien standen dabei im Vordergrund: Die zu entwickelnden Suchwerkzeuge sollen die Nutzerinnen und Nutzer in die Lage versetzen, die registrierten Daten gemäß den individuellen Forschungsinteressen maximal auszuschöpfen, und gleichzeitig eine möglichst intuitive Handhabung gewährleisten. Zu diesem Zweck ermöglichen die Suchoptionen des DEMel-Webportals den Forschenden präzise und exhaustive Auswertungen des Datenarchivs. Verbesserungen an Layout und Funktionalität wurden und werden laufend vorgenommen. Um den Nutzerinnen und Nutzern die Entstehungsgeschichte des DEM bzw. DEMel-Projekts, den Umfang und die Funktionen des DEMel zu erläutern, wurde der Bereich Einführung als Informationsseite entworfen. Die Suchoptionen nach Lemmata und Belegen bilden das Kernstück des DEMel-Portals. Bei der Entwicklung der Suchwerkzeuge wurde besonderer Wert darauf gelegt, den Anforderungen und Erwartungen an die Funktionalität einer lexikographischen Informationsinfrastruktur aus Nutzersicht Rechnung zu tragen. Konkret bedeutet dies, dass die Such- und Filtermasken zum einen benutzerfreundlich anhand gestalterischer Konventionen der digitalen Lexikographie entworfen wurden und zum anderen der umfassenden wissenschaftlichen Exploration des Datenmaterials Genüge tun. Auch bei der Einbindung der Bibliografie und des Digitalisierten Zettelkastens standen Nutzungskomfort und Informationsgewinnung im Vordergrund. Zu diesem Zweck wurden die Funktionalität der Website sowie die dort präsentierten Erläuterungstexte permanent verfeinert.
2. Projektphase 2
In der zweiten Projektphase (November 2020 - April 2023) wurden die Arbeiten zur Optimierung der DEMel-Webanwendung fortgeführt, indem Funktionalitäten zur Datenerfassung, zum Datenexport und für Feedback implementiert wurden. Auch in Bezug auf den Datenbestand setzte die zweite Projektphase direkt an der ersten an: Nachdem man aus Zeitgründen zunächst nur eine kleine Auswahl an Informationen von den Belegzetteln erfasst hatte, wurde in der zweiten Projektphase an der Verbreiterung, Vertiefung und Konsolidierung dieser Datenbasis gearbeitet. Dazu zählte auch eine grundlegende Überarbeitung der Bibliografie, bei der zusätzliche Datenfelder hinzugefügt und bereits vorhandene Informationen durch Normdaten angereichert wurden.
2.1 Vertiefung der Datenerschließung
Um den Arbeitsaufwand überschaubar zu halten, wurden bei der Datenerfassung in der ersten Projektphase nur Belegzettel aus dem Fichero DEM nuclear bearbeitet. Zudem wurde für jeden Beleg nur das Lemma mit Wortart, die Belegform, die Quelle in Form einer Sigle und das Vorhandensein eines Mehrwortlexems in die Datenbank eingetragen. Die zweite Projektphase bot nun die Möglichkeit, sowohl weitere Daten von den Belegzetteln zu erfassen als auch zusätzliche Images zu berücksichtigen:
- Zunächst wurden weitere 43.000 Images mit Sekundärbelegen, die aus den Vocabularios I stammen, bearbeitet. Dafür konnte auf die bereits aus der ersten Projektphase bestehende Erfassungsanwendung zurückgegriffen werden. Nach einigen kleineren Anpassungen und dem Import der entsprechenden Digitalisate und Metadaten konnte im Januar 2021 mit der Erfassung der Belege begonnen werden. Innerhalb von 8 Monaten wurden insgesamt 37.443 neue Sekundärbelege in die Datenbank aufgenommen. Sie können nun auch im DEMel-Portal durchsucht werden.
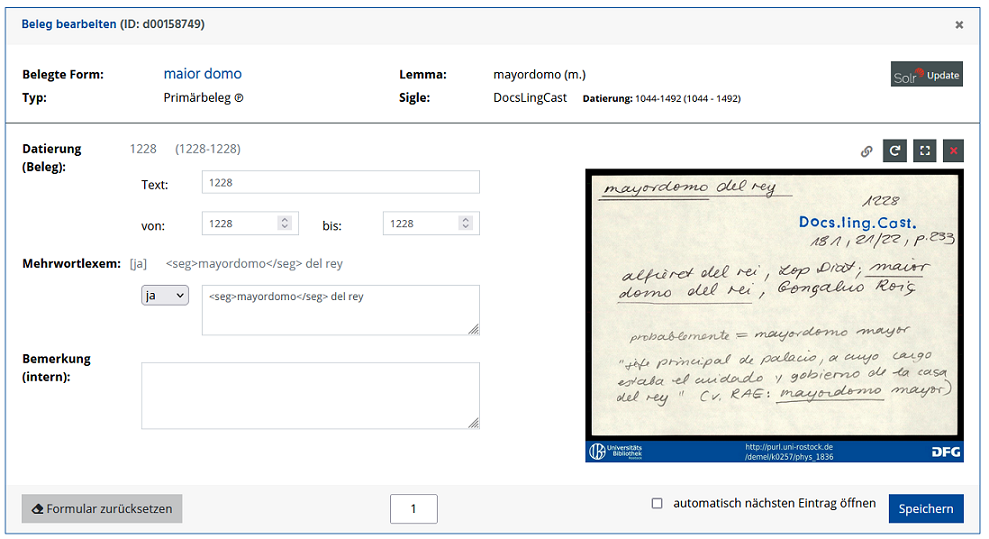
- Im Anschluss wurden die Belegdatierungen präzisiert, die in der ersten Projektphase nur automatisch aus der Quelle generiert wurden. Bei Belegen aus größeren Dokumentsammlungen befindet sich aber häufig die genauere Datierung des entsprechenden Quelldokuments auf dem zugehörigen Image. Im Vorbereitung auf dieses Arbeitspaket wurde daher überprüft, bei welchen Quellen dies der Fall ist und die Belegdatierungen nachgetragen werden können. 272 Quellen wurden ermittelt, die mit rund 110.000 zu bearbeitenden Belegen verknüpft waren. Für die Erfassung der Datierungen wurde das DEMel-Portal um eine erste, limitierte Version eines Editors zum Bearbeiten von Belegen erweitert. Damit wurden zwischen Oktober 2021 und Februar 2022 die genaueren Datierungen der jeweiligen Quelldokumente erfasst.
- Parallel zu den Datierungen wurden auch die Mehrwortlexeme mit dem Editor in die Datenbank eingegeben. Bereits in der ersten Projektphase hatten die studentischen Hilfskräfte die Belege markiert, bei denen ein Mehrwortlexem vorhanden ist. In der zweiten Projektphase wurde nun der genaue Wortlaut in die Datenbank eingegeben. Dadurch ist es jetzt möglich, die rund 57.500 Mehrwortlexeme automatisch zu durchsuchen.
2.2 Überarbeitung der Bibliografie
Nach der Vervollständigung der Bibliografie in der ersten Projektphase fand zum Ende der zweiten eine umfassende Überarbeitung statt, um sie mit weiteren Informationen anzureichern und ihre Durchsuchbarkeit zu verbessern. Das beinhaltete zunächst die systematische Suche nach im Internet verfügbaren Digitalisaten von Quellen, die im positiven Fall mit der jeweiligen Edition verlinkt wurden. Anschließend wurde die Bibliografie um zusätzliche Datenfelder wie Textsorte, Sprache, Genre und Autor erweitert und die entsprechenden Daten für alle Primärquellen in Tabellenform erfasst. Dabei orientierte man sich am Old Spanish Textual Archive (OSTA) und der Bibliografía Española de Textos Antiguos (BETA). Schließlich wurden die bibliografischen Einträge, sofern möglich, mit Normdaten, z. B. von der Biblioteca Nacional de España, verknüpft. Um die Erfassung der neuen Informationen zu ermöglichen, musste das DEMel-Datenmodell überarbeitet werden. Im Bereich der Bibliografie wurden zu den "Werken", "Editionen" und "Siglen" die Entitäten "Reproduktionen" und "Personen" ergänzt.

2.3 Weiterentwicklung des DEMel-Portals
In der zweiten Projektphase wurde die DEMel-Webanwendung zu einer ausgereiften Version weiterentwickelt. Optimiert wurden neben Suchen, Filter und Facetten auch die Trefferlisten, Viewer und Detailansichten. Neu implementiert wurden die folgenden Funktionalitäten:
- Wie bereits erwähnt, wurde das Webportal um ein Editormodul zur Datenerfassung und -bearbeitung erweitert. Anfänglich nur für die Erfassung von Mehrwortlexemen und Datierungen vorhergesehen, wurde es zum Ende der Projektphase optimiert. Nun ist auch die Bearbeitung von weiteren Belegdatenfeldern und von Lemmata möglich.
- Dank einer Feedbackfunktion haben die Nutzer die Möglichkeit in der Lemmaliste, in den Belegen und in der Bibliografie auf Fehler hinweisen oder öffentliche Kommentare abzugeben. Über diese Kommentarfunktion werden auch Änderungen im Datenbestand nachvollziehbar gemacht.
- Die neu erfassten Informationen in der Bibliografie und in den Belegen erforderten eine Überarbeitung des DEMel-Portals. Das umfasste sowohl die Anpassung an das modifizierte Datenmodell, als auch die Anzeige der neuen Daten und die Entwicklung von weiteren Filtern. Dadurch ist es beispielsweise möglich, die Belegtabelle nach der genaueren Belegdatierung zu sortieren oder die bibliografischen Einträge nach ihrer Textsorte auszuwählen. Die Anpassungen gestatten somit noch gezieltere Suchen innerhalb des Datenbestandes. Auch die Schnittstellen zum Datendownload und –export wurden für das neue Datenmodell aktualisiert und um die zusätzlichen Datenfelder erweitert.
3. Projektphase 3
In der dritten Projektphase (Mai 2023 - April 2026) lag der Fokus darauf, die Belegkontexte und die zugehörigen Stellenangaben digital zu erfassen, um damit alle auf den Belegzetteln systematisch enthaltenen Informationen digital zu erschließen. Dafür wurde ein Verfahren zur halbautomatischen Annotation der Belegstellen in den Quellentexten entwickelt. Darüber hinaus wurden auch die bereits publizierten DEM-Wörterbuchartikel in das DEMel-Portal integriert. Schließlich wurden die DEMel-Daten in nachhaltigen und anschlussfähigen Standardformaten bereitgestellt, um ihre Interoperabilität zu verbessern.
3.1 Integration des gedruckten DEM in das DEMel-Portal
Dank der Genehmigung des Heidelberger Universitätsverlags Winter wurden in der dritten Projektphase die drei Bände des Diccionario del español medieval (a–almohatac, 1987–2005) retrodigitalisiert und ins DEMel-Portal integriert. Nach dem Scannen wurden die ca. 2.000 Bilddateien in das Digitalisierungssystem Goobi Workflow der UB Rostock überführt. Dort erfolgte die Paginierung und Erfassung von 50 strukturellen Elementen – darunter Einleitung, Bibliografie, Abkürzungsverzeichnis und eine Gliederung der Wörterbuchartikel in alphabetische Abschnitte – zur besseren Navigation. Für die Volltextgenerierung aus den Scans wurden mehrere Texterkennungstools verglichen: ABBYY FineReader Engine (über Goobi Workflow), Transkribus und OCR4all. Die besten Ergebnisse lieferte Transkribus, da sich damit sowohl ein eigenes Modell für die Texterkennung als auch eines für die Layouterkennung trainieren ließ. Danach wurden die Scans zusammen mit den zugehörigen Metadaten und den erzeugten Volltexten in RosDok, dem Repositorium der UB Rostock, archiviert und über standardisierte Schnittstellen zugänglich gemacht. Über persistente URLs (PURLs) lassen sich sowohl die einzelnen Bände als auch das DEM als Ganzes zitieren. Der RosDok-Viewer wurde in einem eigenen Bereich des DEMel-Portals unter der Bezeichnung „DEM" eingebunden, wo die drei digitalisierten Bände vollständig – mit Titelblatt, Vorwort, Bibliografie u. a. – durchgeblättert werden können.
Für die Integration der Wörterbuchartikel in die DEMel-Datenbank war nur eine einzige Änderung am Datenmodell erforderlich: der neue Typ „print_dem" für die Scans. Ansonsten ließ sich das in den vorangegangenen Projektphasen konzipierte Datenmodell unverändert nachnutzen. Um die Artikel in die Datenbank einzufügen, genügte es, die ID der DEMel-Lemmata sowie die Nummer des jeweiligen Bandes und der zugehörigen Seiten zu kennen. Zu diesem Zweck wurde eine Excel-Tabelle mit einer datenbankgenerierten Liste der Lemmata von a bis almohatac befüllt und anhand der im DEM veröffentlichten Artikel vom Projektteam vervollständigt. Diese Aufgabe bot zugleich die Gelegenheit, die in den vorangegangenen Projektphasen erhobenen Daten zu überprüfen: Schreibweise und Wortart der Lemmata wurden zwischen gedrucktem Wörterbuch und Datenbank abgeglichen. Dabei stellte sich heraus, dass 78 im DEM verzeichnete Lemmata samt ihren Belegen in der DEMel-Lemmaliste fehlten und entsprechend ergänzt wurden. Abschließend wurden SQL-Skripte erstellt, um die neuen Einträge in die Datenbank einzupflegen. Die Wörterbuchartikel sind nun auch über die Belegsuche innerhalb des Portals auffindbar.
Im Zuge der Digitalisierung des DEM wurden zudem 12 urheberrechtsfreie Titel aus der DEMel-Bibliografie, die bislang nicht frei im Internet verfügbar waren, digitalisiert. Diese Digitalisate mit insgesamt etwa 5.000 Images wurden gemäß den DFG-Praxisregeln „Digitalisierung" erschlossen, OCR-verarbeitet, über RosDok bereitgestellt und mit der Bibliografie im DEMel-Portal verknüpft.